Vanilla Policy Gradient
- Exchange derivative and integral operator for a well defined function.
- Re-parameterization trick: Keep the probability density function, so that we can convert the equation back to expectation form, which later can be approximated by sampling in practice.
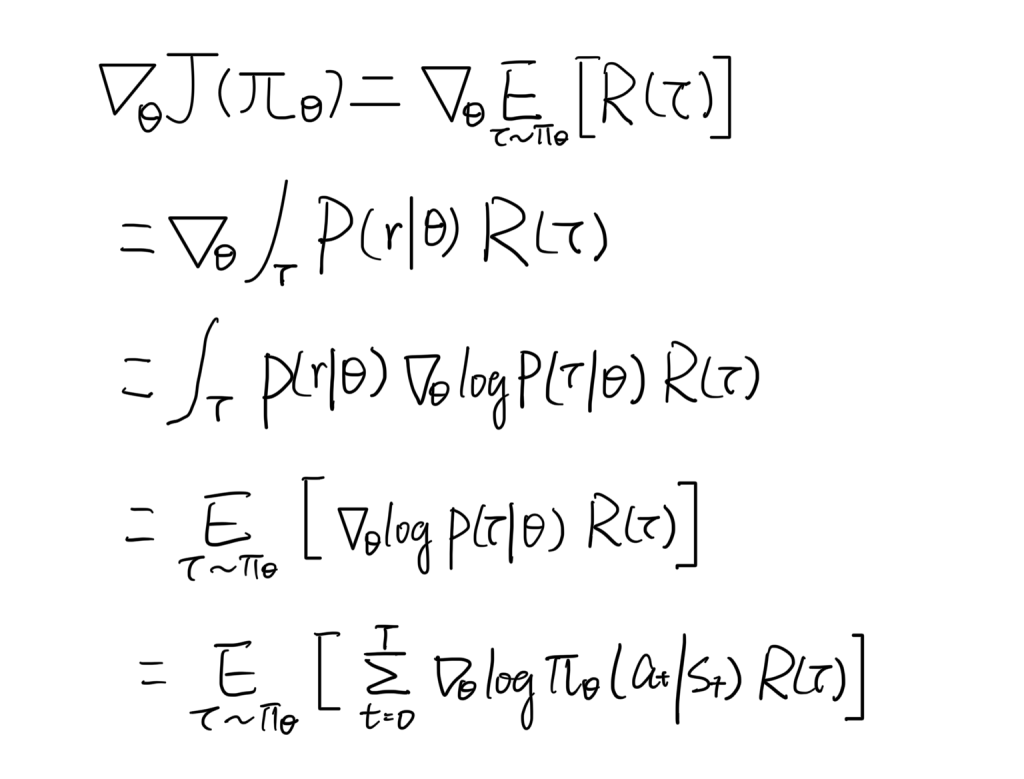
Generalized Advantage Estimate
- Suppose x is a random variable and its probability density is parameterized by θ, P(x|θ).
- Then P(x|θ), log P(x|θ), ▽log P(x|θ) are all random variable.
- The expectation of ▽log P(x|θ) is zero, i.e. E(▽log P(x|θ)) = ∫P(x|θ)▽log P(x|θ) = ∫▽P(x|θ) = ▽ ∫P(x|θ) = 0.
- Any value ɸ, if independent to random variable x, we have ɸE(▽log P(x|θ)) = E(▽log P(x|θ)ɸ) = 0.

Algorithm

Source: https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html#