Before calculating the softmax value in the attention layer, set all logits that don’t fit casual relationships to be negative infinite. I.e. for each token, set all logit values for its successor tokens to be negative infinite.
Calculate the softmax value in the attention layer. For each token, it will only have non-zeros value for tokens before it and have zero value for tokens after it.
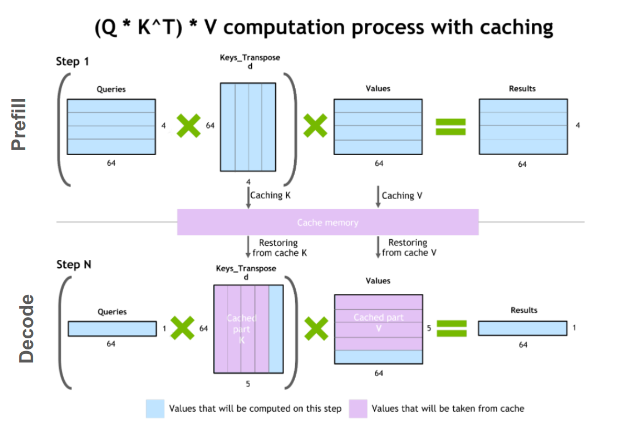
Using cache
Let’s say we also calculate the K, V value for the first three tokens. Now, we have a fourth token.
Use Q, K, V weights to calculate the QueryToken4, KeyToken4, ValueToken4. (batch_size, 1, emb_size)
Concat KeyToken4 to Key cache, get KeyMatrix. For each instance in the batch, it needs to find its own cache (corresponding to a different input sentence) to construct this tensor. (batch_size, 4, emb_size)
Calculate softmax value. (batch_size, 1, 4)
Concat ValueToken4 to Value cache, get ValueMatrix. (batch_size, 4, emb_size)
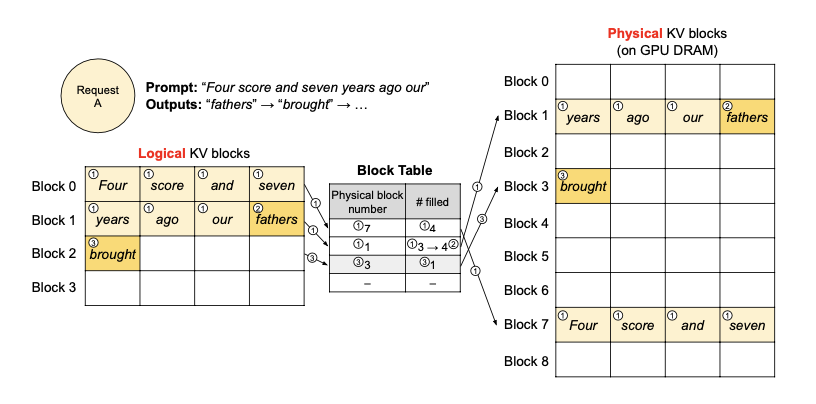
Paged Attention: partition the KV cache into KV blocks. Each KV block contains a KV cache for a fixed number of tokens.
KV Cache Manager: it maintains a block table that maps logical blocks to physical blocks
vLLM: an inference system that implemented Pages Attention. In the decoding phase, it provides logical blocks instead of physical GPU memory to store the new KV cache. It can share KV cache between different decoding sequences and do copy-on-write when these sequences diverge.
Paged KV cache reduce memory wastage:
It reduces internal fragmentations: we don’t need to reserve memory for the possible max length output sequence. We request a new KV block if needed.
It reduces external fragmentations: KV blocks are managed by a centralized manager. There will be no memory waste between different decoding sequences.
It enables memory sharing between different sequences that have the same decoded prefix.